Amazon’s EC2 Container Service (ECS) promises a production-ready container management service but setting it up and running apps on it is not without challenges.
I have been working seriously with ECS for close to a year now, building open-source infrastructure automation tools around all things AWS. While building these tools, running my own production services on ECS, and supporting users in doing the same, I am maintaining a running list of the challenges ECS and containers pose.
Through this lens, I can confidently say that ECS is living up to the promise. It offers flexible options for running apps as containers while offering great reliability for service uptime and and formation management. But it is not trivial to get it all working, and it requires a new way of thinking about our infrastructure and how we build our applications.
ECS Primer
ECS is a set of APIs that turn EC2 instances into compute cluster for container management.
First EC2 instances must call the RegisterContainerInstance API to signal that they are ready to run containers. Next we use the RegisterTaskDefinition API to define the tasks — essentially settings like an image, command and memory for docker run — that we plan to schedule in the cluster. Finally we use the RunTask API to run a one-off container, and the CreateService API to run a long-running container.
All of this works without requiring that we install or operate our own container scheduler system like Mesos, Kubernetes, Docker Swarm or Core OS Fleet.
With all this flexibility we can now map a development workflow onto ECS:
-
Describe our app in docker-compose.yml as a set of Docker images and commands and deploy this onto AWS
-
Scale each process type independently (web=2 x 1024 MB, worker=10 x 512 MB)
-
Run one-off admin containers (
rake db:migrate)
1. Cluster Setup and Automation
The first huge challenge is that ECS is nothing but an API on its own.
We need to bring and configure our own instances, load balancers, logging, monitoring and Docker registry. We probably also want some tools to build Docker images, create Task Definitions, and to create and update Tasks Services.
While ECS has a really slick “first run wizard” and CLI, these tools are probably not enough to manage the entire lifecycle of a serious production application.
The good news is that there are open source projects to help with this. My team is working full time on Convox. The infrastructure team at Remind is building Empire. Both automate the setup of ECS and make application deployment and maintenance simple.
The other good news is that all the pieces we need are available as reliable and affordable services on AWS and beyond. We don’t have to operate a registry, we can use AWS EC2 Container Registry (ECR), Docker Hub or Quay.io. We don’t have to build logging infrastructure when we can integrate with CloudWatch Logs or Papertrail.
Now the challenge we face is picking and configuring the best infrastructure components for a secure and reliable cluster. I recommend:
-
VPC with 3 private subnets and NAT gateways in 3 availability zones
-
EC2 and an AutoScale Groups with at least 3 instances
-
EC2 Container Registry
-
Elastic Load Balancers
-
CloudWatch Logs
We also want to automate the setup and maintenance of these components. I recommend:
-
A CloudFormation stack
-
Resources for the above infrastructure
-
A parameter for the AMI to safely apply OS security updates
-
A parameter for the Instance Type and Instance Count to scale the cluster
We also need to pick and configure the best infrastructure components for a single app or service running on ECS:
-
EC2 Container Registry for app images
-
Elastic Load Balancer for serving traffic and performing health checks on the app web server
-
A CloudWatch Log Group for the app container logs
-
ECS TaskDefinition describing our app commands
-
ECS Service configuration describing how many tasks (containers) we want to run
And this should also be automated with a CloudFormation stack.
As you can see, there is already a huge challenge in what infrastructure is needed and automating its setup before we can run a container or two.
2. Distributed State Machine
ECS, like all container schedulers, is a challenge in distributed systems.
Say we want to deploy a web service as four containers running off the “httpd” image:
web:
image: httpd
ports:
— 80:80
This is simple to ask for but deceptively hard to actually make happen.
To grant our wish, ECS needs to execute this request across at least four instances, but every instance is a black box over the network and poses known challenges.
Sometimes the instance can’t even think about starting the container:
-
Unreachable due to a bad network
-
No capacity due to running other containers
Sometimes it can try to start a container but not succeed:
-
Errors pulling an image due to bad registry auth
-
Errors starting a new container due to a full disk volume
-
Application errors cause the container to crash immediately
And it is guaranteed that an instance won’t run the container forever due to:
-
Hardware failures
-
Scheduled AMI updates
To handle all these challenges ECS needs to very carefully tell the instances what to do in the first place, collect constant feedback from the hosts and from the network, and very carefully tell the instances to do new things to route around failures.
This all represents a tough fundamental problem computer science: distributed state machines. We defined a desired state — 4 web servers — but a coordination service needs to:
-
Maintain a consistent view of containers running in the cluster and the remaining capacity on every instance
-
Turn the desired state into individual operations, i.e. start 1 web server with 512 MB of memory
-
Ask instances with capacity to execute these operations over the network
-
Retry operations if errors are observed
-
Retry operations if no success is observed
-
Constantly monitor for unexpected state changes and retry operations
-
Route around any failures like network partitions in the coordination service layer
This is tremendously hard to do right.
The best solutions need a highly-available consistent datastore which is best built on top of complex consensus algorithms. If you’re interested in how these distributed state machines generally work I recommend to research the Paxos and Raft consensus algorithms.
Werner Vogels shares more about the sophisticated engineering AWS uses to pull it off on ECS here. This brain behind ECS needs to always be available, always know the desired state, constantly observe the actual state, and perfectly execute operations to converge or reconcile between the two.
Thank goodness we don’t have to write and operate this system ourselves. We just want to run a few web servers!
Still, when deploying to ECS we can expect to occasionally see side effects of the distributed state machine. For example, we may see extra web processes if the ECS agent on one of our instances loses touch with the coordination service.
3. Application Health Checks and Feedback
Consider one more evil scenario… Our app is built to not serve web traffic until it connects to its database, and the database is offline or the app has the wrong password. So our web container is running but not able to serve traffic. What should ECS do?
For this, the ECS integrates deeply with one other service as watchdog: ELB. ELB is configured with rules to say if a container is healthy with respect to actually serving HTTP traffic. If this health check doesn’t pass, ECS has to stop the container and start a new one somewhere else.
So we now find ourselves imposed with strict rules about how our applications have to respond to HTTP responses. The health check is very configurable, but in general our app needs to boot cleanly in 30 seconds and always return a response on /check or else ECS will kill the container and try again somewhere else.
A bad deploy that doesn’t pass health checks can cause trouble.
4. Rolling Deploys
A side effect of the distributed state machine is that apps are now always deployed in a rolling fashion. On a service update ECS follows a “make one, break one” pattern, where it only stops an old task after it successfully started a new one that passes the ELB health check.
This is extremely powerful. The system always preserves the capacity you asked for. It carefully orchestrates draining existing requests in the ELB before removing a backend.
But this poses challenges to how we write the apps we are deploying to ECS. It is guaranteed that 2 versions of our code will be running occasionally.
Our software needs to be okay running two different versions at the same time. Our clients need to be okay talking to two different API versions in the same session. Two different releases of our software need to be ok talking to the database before, during and/or after a schema migration.
5. Instance Management
Even though we are now running containerized workloads ECS does not hide the fact that there is a cluster of instances behind our containers. Traditional instance management techniques still apply.
Our cluster should be in an AutoScaling Group (ASG) to preserve instance capacity. We still need additional monitoring, alerting and automation around instance failures that EC2 doesn’t catch.
We also need to be able to apply AMI updates gracefully, so having CloudFormation orchestrate booting a new AMI successfully before terminating an old instance is important (make one, break one for our instances).
I’m observing that right now that great instance management even more important than before, as heavy container workloads can be more demanding on an instance, and are exercising some fairly new corners of the kernel, network stack and filesystem.
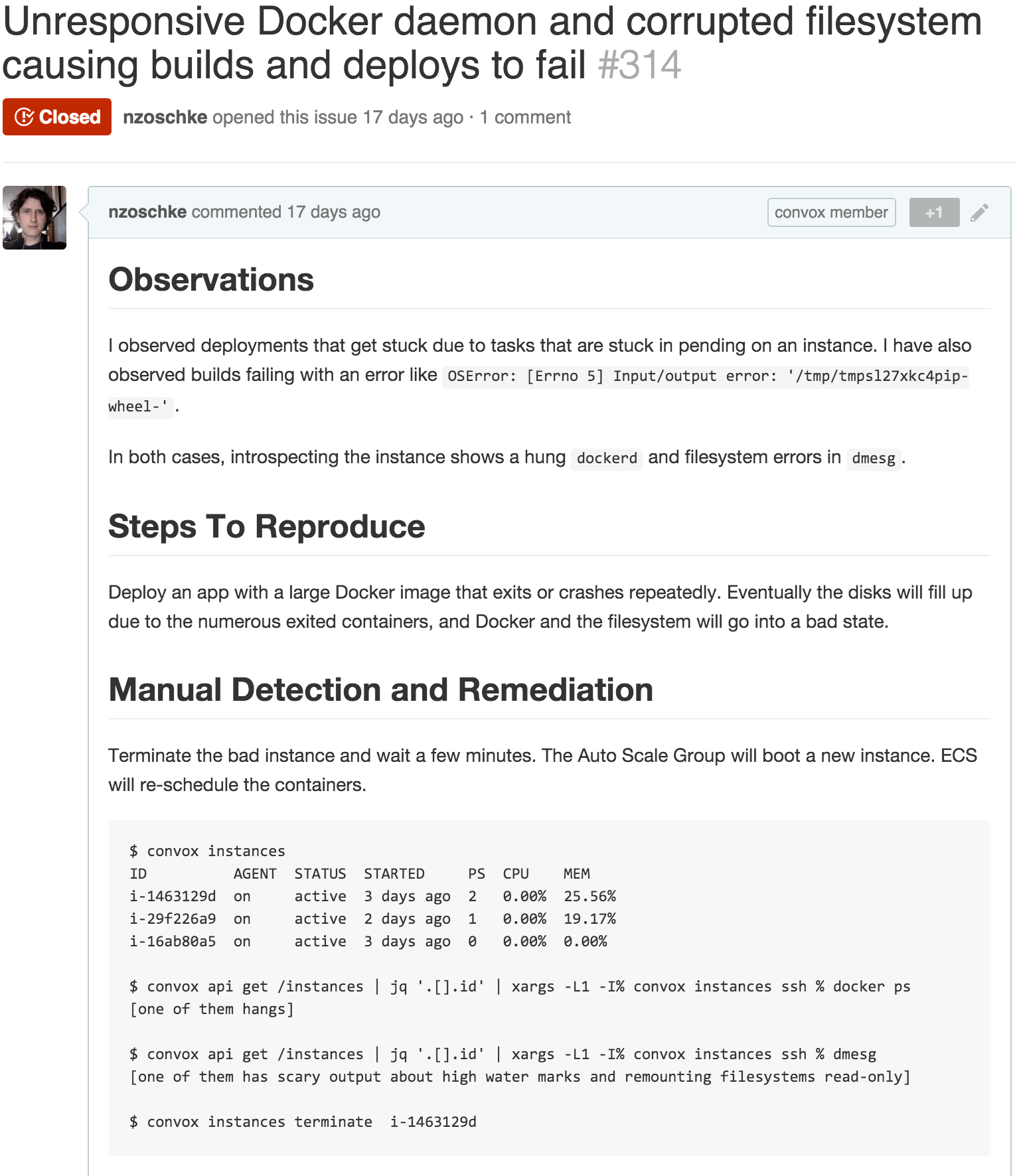 Filesystem lockups in production: https://github.com/convox/rack/issues/314
Filesystem lockups in production: https://github.com/convox/rack/issues/314
6. Logs and Events
Container logging is a challenge all to itself.
Both Docker and ECS have a well understood historical gap in this space, originally launching with little tooling built into to help with application logs. For apps with real logging demands it is often left as an exercise to the app developer to bake in log forwarding logic into the container itself.
Thankfully this is all improving due to the recent excellent Docker logging drivers and ECS optionality to pick and configure one.
Still, the dynamic and ephemeral nature of containers causes challenges. When our containers more frequently stop and restart on new instances, we probably want to inject task ids, container ids and instance ids into the log streams, and the Docker logging drivers don’t really help with this.
So it might still be our responsibility to include more context in our application logging.
Finally we could almost certainly use even more context from all of ECS injected into our application logs to make sense of everything. Knowing that a container restarted onto a new host due to a failure is valuable to see in the app logs. The start and absolute end of our rolling deploy would be nice to see too.
None of this comes out of the box on ECS.
The best solution is to run an additional agent as a container on every instance:
-
Monitor all the other containers
-
Subscribe to their logs
-
Add more context like instance and process type
-
Forward logs to CloudWatch
As well as to run another monitor container somewhere that:
-
Periodically describes ECS services
-
Monitors deployment status
-
Synthesizes these into coherent events like “deployment started” and “deployment completed”
-
Sends notifications
Without effortless access to application logs and ECS events it can be extremely challenging to understand what is going on inside the cluster during deployments and during problems.
7. Mental Challenges
All of this adds up to a complex system that is often hard to understand, reason about, and debug.
There’s no way to predict exactly how a deployment will be carried out. What instances the 4 web containers land on and how long it takes to get there can not be predicted, only observed.
You can easily make 2 or more UpdateService API calls in rapid succession. If you start with 1 web process, ask for 10, then quickly change your mind and ask for 5, what are the expectations while ECS carries out these deployments?
It’s actually quite easy to get the system in a state where it will never converge. Ask for 4 web processes but only run 2 instances in your cluster, and watch ECS quietly retry forever.
And the actual formation of our containers are constantly changing from under us due to our application code and the underlying hardware health.
ECS, ELB, ASG and every process type of all our apps feed back on each other and somehow need to end up in a steady state.
Conclusion
In many ways ECS is significantly more challenging than EC2/AMI based deployments because its an entirely new layer of complexity on top of EC2.
This always leaves me with a nagging question…
Is ECS worth it?
I ask the same question to you… Have you experienced these or challenges on ECS? Have you solved them and happily got back to deploying code? Or have you pulled your hair out and second guessed the tools and the complexity?
Thankfully I’ve had enough success overcoming these challenges on ECS that I’m not looking back.
Deployments are faster and safer than ever before. All the complexities of the distributed state machine represent the most sophisticated automation around running apps that we’ve ever had. This is extremely sophisticated monitoring algorithm constantly working to verify that things are running so us humans don’t have to.
Finally its still the early days for all of these tools. ECS started out rather spartan, then Amazon released the ELB integration, then announced ECS, and recently added more deployment configuration.
I fully expect Amazon will continue to chip away at these hard infrastructure parts and Docker will continue to improve the container runtime.
We will get to focus the vast majority of time building and deploying new versions of our apps and trust that the container services will keep everything running.
I work full time on open source infrastructure automation at Convox (website, GitHub).
Please send feedback and/or questions Twitter to @nzoschke or email to noah@convox.com.
Thanks to Mackenzie Burnett, Eric Holmes, Calvin French-Owen and Malia Powers among others for feedback.